
第2回:理解の価値とは何か
本記事は、ブログ連載「AIと生きる時代の〈理解〉考」の第2回です。前回から2か月以上開いてしまいましたが、この間もずっと本記事のことを考えていました。ようやくストーリーが固まってきたので、書いてみます。
第1回はこちら⇩
【AIと生きる時代の〈理解〉考】第1回:LLMは理解しているのか?
- なぜ、AIが理解していると言いたくないのか
- なぜ理解に価値があるのか
- 理解は単なる知識ではない
- 「できる」につながらない理解?
- 理解していなくても「できる」こと
- ここまでのまとめ
- おわりに
- 謝辞
- 参考文献
***
なぜ、AIが理解していると言いたくないのか
この連載の第0回では、次の問いを立てた。
昨今のLLM(大規模言語モデル)の能力を所与の事実として踏まえたときに、私たちはどのような新しい理解観を持つことができるか?
数年前に、LLMという装置が現れた。これは言葉を操るAIであり、いままでは人間にしかできないと思われていたような能力をもつ。まるで理解しているかのようだ。このことは、私たち人間が何かを理解する理由や方法にどのような影響があるだろうか。そもそも理解とはなんだったのだろうか。AIと生きる時代に適した「理解についての理解」が必要とされているのではないか。そう考えて、本連載を始めたのだった。
前回は「LLMは理解しているのか?」と題して、LLMを中核としたAI自体が、文章を理解しているように見える現象について扱った。AI研究者たちの多様な意見からは、次のことが確認できた。
- AIは、人々がイメージする「理解する機械」に、予想以上の早さで近づいた。
- それでも、人間の理解と同じとは言えない、あるいは言いたくない感覚も残る。
AIはあたかも理解しているかのように言葉を操るが、それだけをもって「理解している」と言うのも違う気がする。この躊躇の最大の理由は、AIが言葉を処理する仕組みにあると思われた。今日の生成AIは、与えられた文字列(トークン列)に対して、次にどのような単語が統計的に出てきやすいか、あるいはユーザーが求めているかに関する確率分布に基づいて文を生成する。このような文章生成は、私たちの感覚では「理解したうえでの言語運用」とはまったく異なるもののように思われる。私たちは決して確率分布から単語をとってきているのではなく、理解したうえで言葉を選んでいるんだと言いたくなる。
AIはどこまでも理解している「ふり」をしているだけだ。そのはずなのに、AIは流暢に言葉を返してくるし、その思考力は月日を経るごとに深くなっている。岡野原大輔氏が「現象論的には」AIは理解していると書いたように、振る舞いのうえでAIは理解しているとしか思えない。
前回はそのように考えてきて、次のことに思い至った。私たちが向き合っているのは「理解とは何か?」という問いではなく、むしろ「私たちはどのように理解という概念を使いたいのか?」という問いなのではないか。AIの理解は本当の理解ではないと言いたくなるとき、私たちは理解の何を守ろうとしているのだろうか、それを先に考えるべきではないだろうか。
そこで今回は、理解と私たちが呼ぶものの価値について考える1。なぜ理解が大事な気がするのか。それを考えることを通して、今回と次回では、AIと生きる時代の理解の暫定的な作業モデル(working model)をつくっていきたい。
なぜ理解に価値があるのか
「AIは本当は理解していない」と言いたくなるのは、人間のなかにもそういう人がいるからかもしれない。「理解が浅い」「理解を装っているだけ」の人が私たちの周りには多くいる。SNSでは専門家風の人の理解が、実は表面的であることが露呈する。専門性を期待して採用された中途社員が、実は期待した理解をもっていないことにだんだん気づく…。こういう経験からわかるように、理解は「見せかける」ことができる。
理解を試すための仕組みとして、学校教育のなかで実施されている定期テストや入学試験がある。しかし、テストは理解の完全なリトマス試験紙ではない。理解していればテストが解けるが、テスト問題が解ければ理解しているとは限らないからだ。筆者が中学生のときに、筆者のことを「ペーパーテスト人間」と呼んだ友人がいた。テストに最適化された薄い知識しか持っていないと言いたかったのだろう。腹が立ったが、当たらずとも遠からずだったような気もする。テストで100点をとれたとしても、その科目を100%理解していたわけではないからだ。
ペーパーテストを解く能力は理解とイコールではない。科目の内容を理解せずに、ヒューリスティック、つまり何らかのルールやテクニックを使ってテストで高得点を取ることはできる。これは、中国語を全く理解していないにもかかわらず、マニュアルに従うことで理解しているかのように振る舞うことができた、ジョン・サールの「中国語の部屋」の状況そのものだろう(第1回参照)。
学校教育は当然、テストで良い点数を取る能力ではなく、科目の内容を生徒が理解するようになることを目指している2。理解に価値があるのは、テストを解ける以上のことができるようになるからだ。ラジオの仕組みを理解していれば、ラジオが壊れたときに直せる。線形代数を理解していれば、機械学習のアルゴリズムを設計できる。簿記を理解していれば、経理の仕事を回すことができる。友人の気持ちを理解していれば、悩み相談に乗ることができる。ペーパーテストを解ける「だけ」の人には、どれもできないだろう。
理解は単なる知識ではない
こう考えると、理解とは単なる知識ではない。私が知っているものごとのうち、理解しているものごとはその一部だ(下図)。

理解していることは知っていることの一部分
文献を紐解くと、この理解と知識の違いというトピックは、近年の哲学的認識論でもよく議論されている3。その代表的な論者の一人である、スティーブン・グリム(Stephen Grimm)は「理解の価値」という論考の中で、単に知っていること(命題的知識と言われる)と理解していることの違いをニュートンの第2法則(F=ma)を使って説明している4。
まず、私がニュートンの第二法則を先生の言葉を頼りに受け取る場合を考えてみよう。そのとき、私の心は世界を正確に反映(mirror)している——つまり正しく把握している——が、その反映はきわめて表面的なものにとどまる。私は世界のあり方に関する正確な情報を含む命題に同意してはいるものの、私の心は作業を実際に引き受け(take on)、やって(do)はいないのだ。では、私の心が現実をより深いレベルで反映し、実際にそのはたらきを引き受けるとはどういうことか。…必要なのは、その法則が記述する要素や性質が互いにどのように依存し合っているかを把握すること——すなわち、ある要素の値が変化したとき、他の要素の値がどのように変化する(あるいは変化しない)かを把握することだと思われる。そうなったとき、心は以前よりも深く世界を反映するようになる。なぜなら心は今や世界の法則的構造を引き受けたことになるからであり、把握した構造が、単に命題に同意していたときにはできなかった仕方で、心に情報を提供するようになる。(Grimm 2012、筆者訳)
一見難しいが、ゆっくり読めば理解できる。この世界の物体がF=maという法則に従うことを教わったとする。それだけでは、ニュートンの第2法則を理解したことにはならない。理解したと言えるためには、F=maを使えなければならない。F=maを使うというのは、鉄球が落ちるとか振り子が触れるとか惑星が周転するとか、いろいろな設定でこの法則を適用し、実際にその帰結を導くことができるということ。まさに、高校物理の「力学」の単元で私たちがさんざん練習してきたことだ。
F=maの例に限らず、何かを理解するというのは、単に知識をもつことではなく、動かせるモデルを自分のなかにもち、そのモデルの変数がどう変わったらその帰結がどうなるかをシミュレートできる状態になることだと言える。ある命題を暗記しているだけでは十分ではない。それは「なぜそうなのか」「もし条件が異なったらどうなるか」という反実仮想的な思考を可能にするものでなければならない5。たとえば、「鎌倉幕府の第一代将軍は源頼朝である」という知識を持っているだけでは理解とは言えず、「なぜ源頼朝は鎌倉に幕府を開いたのか」といった理由を問う質問(why question)に答えたり、「もし鎌倉以外の地が選ばれたらどうなっていたか」(what-if question)に対する推論ができるとき、鎌倉時代について理解していると言われる。
理解している人は、できることが増える。友人の誕生日パーティを企画することになったとする。どのお店を予約するか、誰を呼ぶか、どんな機材が必要で、余興の準備は誰に頼むか。良いお店を知っているというだけではなく、パーティを企画するとはどういうことかに関するよいモデルを持つ人は、自分の選択の結果をあらかじめイメージし、先回りしてトラブルシュートし、大体思い描いた通りのプランを実行できる。理解というモデルを持つことによって、私たちは自分で行動を行う前に、自分たちの行動の帰結を推論することができる。理解がなければ、人生は無鉄砲な試行の連続になってしまう。
ここまでの話をもとに「理解の価値とは?」という最初の問いに答れば
理解に価値があるのは、できることが増えるから(★)
となる。これ以上ない、常識的な結論だ。しかし、本連載の目的からすると、ここで終わるわけにはいかない。なぜなら、この「できることが増えるから理解には価値がある」というこれまでの理解観が、ぐらついているように思われるからだ。だから、この先をこそ考えなければいけない。
★に対して、すぐに二つの疑問が浮かんでくる。
- Q1. 理解の価値は本当に「できるようになること」だけなのか?
- Q2. 理解しなくてもできることはあるのではないか?
ここまでは、「できる」こと、つまりある種の能力(ability)につながる知識として理解を捉えてきた。しかし、「理解している」と「できる」ということは、完全には重ならずこの二つのギャップがあるように思われる(下図)。以下ではこれらについて考える。そこから見えてくるのは、理解には理解する主体である「私」にとっての固有の価値があるということだ。

理解とできるの間の二つのギャップ
「できる」につながらない理解?
理解の価値は、何かができるようになることだけではない気がする。認識論の教科書を紐解いても、知識の価値として非道具的価値が出てくる6。道具的というのは、何か他のことの手段としての価値という意味である。理解や知識の非道具的価値というのは、何か別のことに役立つからだけでなく、それ自体としての価値のことだ。
理解にいつも道具的な価値を求めるのは、「その研究は何の役に立つんですか?」という問いに通じるある種の了見の狭さが漂う。ブラックホールの仕組みや数億年前に絶滅した生物の生態など、私たちは生涯に「使う」当てのない物事の理解を求め、それに価値をおいているようにも思える。
このことを考える時にいつも思い出すのが、漫才コンビ・オードリーの若林正恭さんのエピソードだ。2017年のエッセイ書『表参道のセレブ犬とカバーニャ要塞の野良犬』によれば、若林さんは(おそらく40歳に近い年齢で)大学院生の家庭教師を雇っていた。その家庭教師に若林さんは世界経済について学び、さまざまな疑問を投げかけていたという。
「…「なぜブラック企業が増えたのか?」「なぜ交際相手にスペックという言葉が使われるようになったのか?」…それらの疑問を投げかけたぼくに家庭教師は「若林さん、世界史の教科書の産業革命以降を読んでください。あと、経済学入門と日本史の教科書の戦後以降も…」と言った」(若林 2020, p. 26)
このエッセイで、若林さんは自分が埋め込まれた世界の仕組みを「理解」しようと世界を旅する。自身が生活する東京と真逆の社会システムを見学するため、社会主義の影響が色濃く残るキューバへの一人旅も実行する。自分の人生の背景にあるシステムの構造を理解したいと希求し実際に行動する若林さんの態度が、私は素敵だと思う。
若林さんに限らず、私たち人間はこのような一見なんの現世的な「役に立つ」にも還元されない理解を目指してきたように思われる。自分たちがどこからきたのか、世界はどのように今のような姿になったのかという、ある種のストーリーを求めている。
知りたいから知りたい。理解したいから理解したい。知識の哲学(認識論)では認識的価値(epistemic value)とも言われるこうした価値は、「できることが増えるから」という現世的な価値とは質の違うもののように思われる。しかし筆者は、これをプラクティカルな理解と連続したものと捉えたい。
私たちは、たとえばF=maや線形代数や簿記を理解することで、自らの目的(aim)に沿って行動(action)をとることができる。しかしこの目的というのも、私たちの生活のなかで変わる。6歳のころの人生の目標を、30歳になっても持ち続けている人はほとんどいないだろう。私たちは生きるなかで「やりたいこと」を変えていく。この変化をもたらすのが、一見非道具的に見える理解の機能とは言えないだろうか。つまり、理解というのは「できることを増やす」だけでなく、「何をやりたいかと思うかを変える」作用をもつ。
若林さんが、家庭教師からグローバル経済を学び、キューバに足を運んで異なる社会制度のもとで暮らす人々のことを知りたいと思ったのは、自身の人生の進む方向性を見直すというメタな目的があったのだと思う。理解には、壊れた機械をなおすとか、事業を成功させるといった直近の目的達成に役立つだけではない。そもそもその機械がなんのためにあるのか、達成すべき事業はなんなのかという自身の行動を意味づけることでもある。宇宙の銀河系の離合集散についての理解も、数億年スパンの生命進化についての理解も、その意味では、広義の「役にたつ」に含まれる。私の理解は、私に何かをできるようにしてくれることに加えて、今はできるようになりたい/理解したいとさえ思わないことを含め、できること/理解できることの範囲をさらに広げてくれる。
理解していなくても「できる」こと
理解と「できる」を同一視する見方(★)へのもう一つの疑問として、何かができるために必ず理解が必要なわけではないだろう、というものがある。たとえば、理解していなくても、身体が勝手に動くということがある。一輪車に乗っている小学生は、一輪車の乗り方を「理解している」のだろうか。これは身体に身についた技能ではあるが、狭い意味での「理解している」というカテゴリーからは外してよいだろう。これもある種のモデルを学習することに当たるが、知らず知らずに身につく身体知7と、F=maを理解する場合とはひとまず区別すべきように思われる8。
一方で、本稿にとってより重要なのは、理解を持たなくても「できる」ようになっていることが増えているようにみえることだ。たとえば、私はWebサイトづくりのためのコーディングをやったことなどなかったが、最近のClaude Codeおよびそのノーコード版のClaude Coworkによって半日でつくることができてしまった9。エンジニアとしてOpenAIやテスラの中核的な役割を担ったアンドレ・カーパシー(Andrej Karpathy)はこれをVibe Codingと呼んだ。
Vibe Codingをしている私はプログラミングを理解したのかといえば、明らかにしていない。しかし、私の行動を外から見ている人からは、理解しているように見えるかもしれない。サールは中国語を理解していないが、サールが入った中国語の部屋は中国語を理解しているように見えるのと同じだ。私やサールには理解というモデルがないにもかかわらず、Claude+私、あるいは中国語のマニュアル+サールは、プログラミングや中国語を理解しているように見える。
ここで起こっているのは、外部モデルの利用である、ということができる。自分の中にないモデルを、外にあるモデルに頼っているということだ。Claudeはプログラミングについて、中国語マニュアルは中国語について正しいモデルを持っているだろう、という信用のもとに、それらに頼っている。いわば、理解のアウトソースがなされている。これは、人と機械の間だけでなく、人の間でもつねに起こることだ。経理担当者が持っている経理についての理解を信用して任せる、など。このように、理解を他者や機械という外部モデルに依存しあうことで、私たち人間は集団として個人では到底できないことができるようになる(湖をせき止めてダムをつくる、1億人から税金を徴収する、etc.)。
したがって、「理解してなくてもできる」ということには、重要な留保がつく。それは「頼っている外部モデルが信用できる限りにおいて」という留保だ。考えてみれば、中国語マニュアルに一言一句従って動くサールは異常なまでにそのマニュアルを信用している。私もかなりの程度、Claude Codeを信じている。この信用が裏切られない限りにおいて、「理解していなくてもできる」という状況が維持される10。他者や道具やAIを介した理解のアウトソースは、その他者や道具やAIが信用できる場合にのみ自分の「できる」につながる。
ただし、内部モデルと外部モデルは密接にリンクしている。先生から何かを教わるというのは、先生の外部モデルを自分の内部モデルに取り込むことだ。こうした内部モデルと外部モデルの相互作用は、次回以降の課題としたい。ここで言えるのは、前節でみたような「自分が何をしたいのか/理解したいのか」を見つけるための理解は、決して外部モデルにはアウトソースできないということだ。
ここまでのまとめ
ここまで見てきたことを振り返ろう。本稿は、「理解の価値とは何か?」という問いから出発し、いったんは「対象のモデルを自分の中に持つことで、何かができるようになるからだ」という答えを得た。単なる知識(下図のA)とは異なり、理解していることで、私たちは何かができるようになる(図のB1)。
しかし、何かをできるようになるということを超えた理解の価値として、そもそも何をやりたいのかを見つけることにも理解はつながる(B2)。また、理解とは異なるが「できる」につながる身体知(D)の存在に軽く触れた後、外部モデルを信頼することで私たちは知っていないこともできる(C)ことを見た。ただし、その場合にも自分が何をしたいのか/理解したいのかを探すという理解は代替できない。
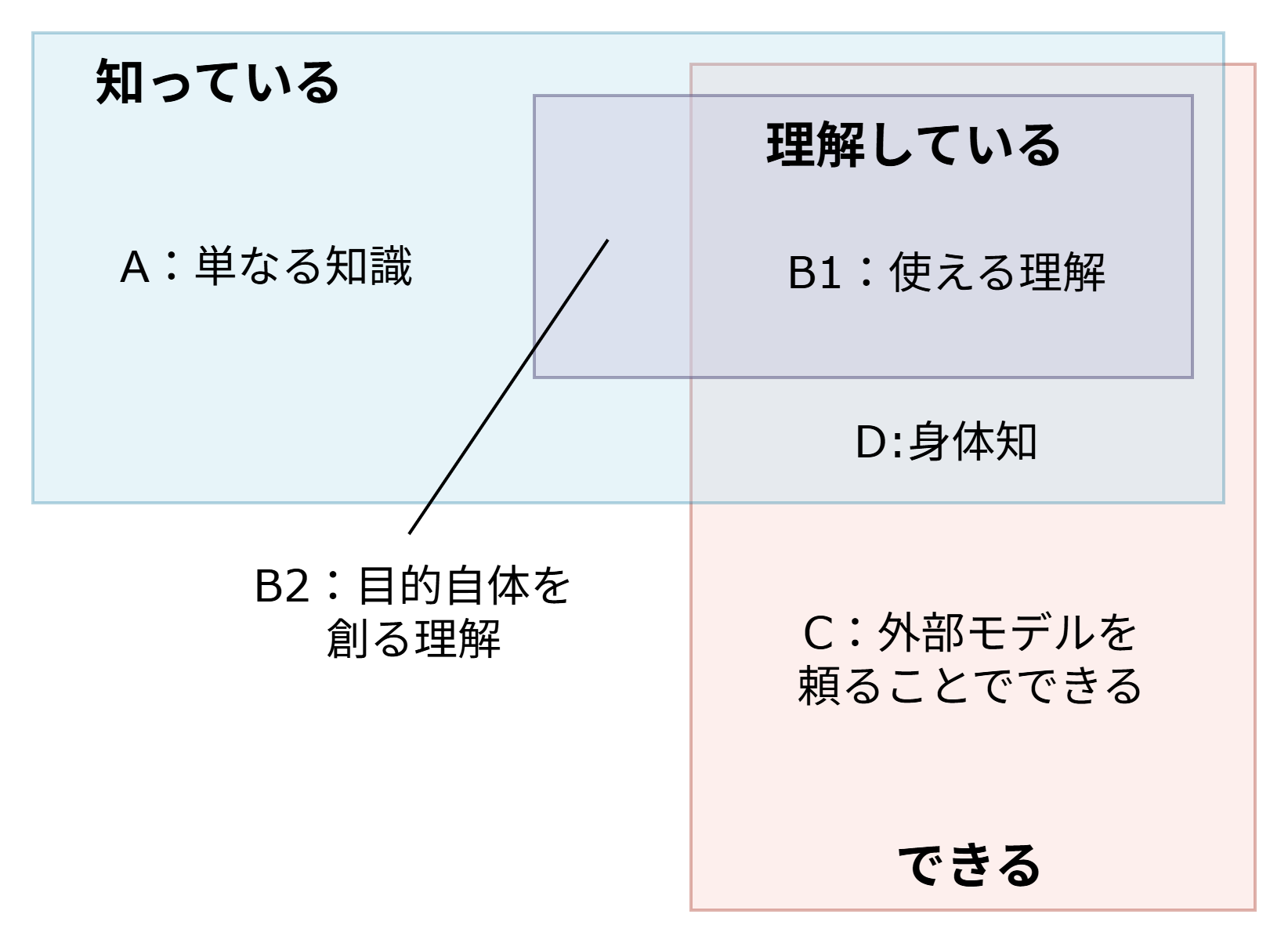
「知っている」「理解している」「できる」の関係
このように、私の理解というのは世界の中で生き、何かを知ったり理解したり、知らなかったり理解しなかったりしながら、この世界で行為する主体である私にとって固有の価値を持つ。こうした、世界のなかで知り、理解し、行動する主体を、科学哲学者のハソク・チャンは認識エージェント(epistemic agent)と呼ぶ(Chang 2022)11。この言葉を使えば、本稿の結論は以下のようになる。
理解とは、認識エージェントが世界についてのモデルを内部に持つことであり、それは認識エージェントに自分のやりたいことを発見し、実行する(=できる)能力を与える。
おわりに
前回は「AIは本当に理解しているのか?」という問いを扱った。この問いの背景にあるのは、「人間の理解」というものがあり、それとは「AIの理解(っぽいもの)」があり、それらを比較しようという発想だろう(下図の左)。当然、脳と人工ニューラルネットワークの仕組みの違いを考えれば、両者に大きな違いはあるだろう。
しかし、本稿で扱ってきた理解の「価値」の議論からすれば、人間の理解とAIの理解の違いよりも、自分の理解と自分以外の理解の違いの方が大きいことに気づく(下図の右)。なぜなら、自分にとっては、自分の理解とは本稿でいう「内部モデル」であり、自分以外の認識エージェント(epistemic agent)であるところの他者やAIの理解は「外部モデル」であり、その意味では同列にみなすことができる。このように問題を捉え直すことが、AI時代の理解考ではとても重要なことだと考えている。
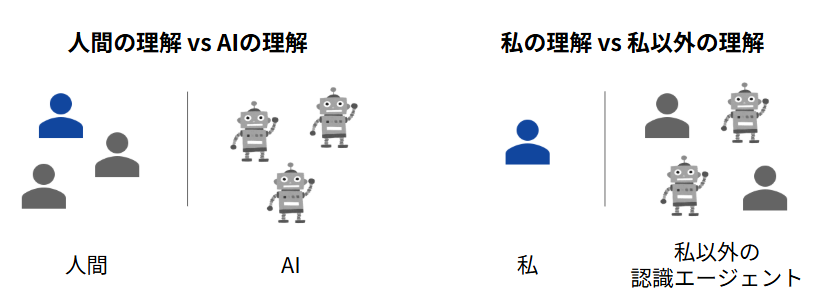
より根本的な区別は自分と自分以外?
本稿では内部モデルの獲得として理解を捉えたが、実際にこのモデルはどのようなものなのか。その獲得と更新はどのように起こるのか。それを考えることが次回のテーマとなる。そこでは、機械学習の「世界モデル(world model)」の概念を中心におきながら、理解の作業モデルをつくってみたい。内部モデルと外部モデルがどのように関係し合うのか、また理解は個人的なものでありかつ公共的なものであるとはどういうことかについて、手触りのある理解の理解をつくることを目指したい。
謝辞
公開前の原稿に目を通しコメントをいただいた皆様に御礼申し上げます。
参考文献
- Gopnik, A. (2000). Explanation as orgasm and the drive for causal understanding: The evolution, function and phenomenology of the theory-formation system. In F. Keil & R. Wilson (Eds.), Cognition and explanation. Cambridge, MA: MIT Press. pp. 299–323.
- Wiggins, G., & McTighe, J. 西岡加名恵訳(2012)『理解をもたらすカリキュラム設計:「逆向き設計」の理論と方法』日本標準.
- Grimm, S. (Winter 2025 Edition). Understanding. In E. N. Zalta & U. Nodelman (Eds.), The Stanford Encyclopedia of Philosophy. https://plato.stanford.edu/archives/win2025/entries/understanding/
- 森田邦久(2025)『理系人のための科学哲学(文庫版)』講談社学術文庫.
- Grimm, S. R. (2012). The value of understanding. Philosophy Compass, 7(2), 103–117.
- Barman, K. G., Caron, S., Claassen, T., et al. (2024). Towards a benchmark for scientific understanding in humans and machines. Minds & Machines, 34, 6. https://doi.org/10.1007/s11023-024-09657-1
- プリチャード, D. 笠木雅史訳(2022)『知識とは何だろうか:認識論入門』勁草書房.
- 若林正恭(2020)『表参道のセレブ犬とカバーニャ要塞の野良犬』文藝春秋.
- ポランニー, M. 高橋勇夫訳(2009)『暗黙知の次元』筑摩書房(ちくま学芸文庫).
- 大屋雄裕(2024)「信用・信頼・信託 ―責任と説明に関する概念整理―」『人工知能』39(3). https://www.jstage.jst.go.jp/article/jjsai/39/3/39_409/_article/-char/ja/
- 山田圭一(2023)『フェイクニュースを哲学する』筑摩書房.
- Chang, H. (2022). Realism for Realistic People: A New Pragmatist Philosophy of Science. Cambridge University Press.
-
理解の価値を考えるうえで、以下の三つを区別は必要かもしれない。(1)理解したまさにその瞬間に得られる価値、(2)理解しようとする努力の価値(3)何かを理解しているという状態の価値。理解した瞬間に得られるある種の喜びがある。発達心理学者のアリソン・ゴプニックによれば、子どもは世界の因果的構造を理論化したいという本能としての「理論形成の動因(theory drive)」を持つ。そして、良い説明(explanation)を得たときのある種の「オーガズム」が備わっているのだと述べた。アハ体験とも言われる。これは、一つ目の、理解という経験に伴う価値だ(Gopnik 2000)。また、理解を目指して努力することそのものに何らかの価値があるという考え方もありうる。「〇〇を学校で教えることにどんな意味があるの?」という問い(〇〇には三角関数、漢文訓読などなどが入る)に対して、その科目の内容自体ではなく、そこで培われる思考力にこそ意味がある、という回答がなされることがある。たしかに、ある対象を理解しようとする努力が、未来のための能力の涵養につながるという価値はありうる。しかし本稿では、より直接的な理解の価値を扱いたい。つまり、理解している状態(state of understanding)の価値だ。ゴプニックのいう我々に備わった理解という事象に伴う快感(1)も、理解という状態に生物学的な価値があるからこそ進化的に人間に備わったものだと考えられるし、理解しようという努力の価値(2)も、別のより価値のある何らかの理解の状態が想定されてこそあると言えるものだろう。 ↩
-
たとえば、Wiggins, G., & McTighe著(2012)『理解をもたらすカリキュラム設計』はいかに生徒に理解をもたらすかという観点から授業のカリキュラム設計を行うかという視点で書かれており、世界中で版を重ねている。 ↩
-
教科書を読むと、認識論の「知識とは何か」という問いはたいていプラトンにさかのぼる(『メノン』『テアイテトス』など)。プラトンやアリストテレスが盛んに議論したキーワードであるギリシャ語の”Episteme”は、伝統的にKnowledge(知識)と訳されてきたが、近年ではこの概念はむしろUnderstandingと訳した方が近いのではないかという意見があるらしい。Grimm, S. (Winter 2025 Edition). Understanding. In E. N. Zalta & U. Nodelman (Eds.), The Stanford Encyclopedia of Philosophy. https://plato.stanford.edu/archives/win2025/entries/understanding/ また、科学哲学者の森田邦久による『理系人のための科学哲学』の昨年末に刊行された文庫版では、数十ページにわたり「理解とは何か」という補章が付け加えられた(森田 2025)。そこでは、従来、知識(knowledge)や説明(explanation)という概念を中心に扱ってきた哲学的認識論や科学哲学のなかで、理解(understanding)に固有の問題が盛んに議論されるようになってきたことが、主要な文献とともに解説されている。 ↩
-
この論文では、単なる(命題的)知識にはない理解の価値として、透明性、より深い世界の反映、理解という達成の価値という三つの説をあげ、それぞれ批判的に分析している(Grimm 2012)。 ↩
-
AIの理解度を測るうえでも、「過去、こうだったとしたらどうなっていたか」「未来に、もしこうなったらどうなるか」という反実仮想的な問い(what-if question)に応えられることが重要となる。科学哲学者も交えたチームは、科学的な理解をしているかを測るベンチマークテストを考案した論文のなかで、ある科学的現象PをエージェントAが理解している条件として「(i)AがPについて十分に完全な表象を有していること、(ii)AがPに関して内的に整合的かつ経験的に妥当な説明を生成できること、(iii)AがPに関連する広範な反事実的推論を正確に導出できること」の三つをあげている(Barman et al. 2024)。 ↩
-
プリチャード(2022)など。むしろ、認識論の伝統では、真理を知るという認識的価値(epistemic value)のほうが出発点になっており、知識の道具的価値は二次的なものとして扱われているような印象がある。しかし個人的には、本連載の文脈や、より広く認識的実践に「使う」という観点からは、後述するHasok Changのようなプラグマティックな真理観、理解観に有効性を感じている。 ↩
-
これについては次回、「世界モデル」の一種としてに扱いたい。 ↩
-
このトピックにとても関連が深いと思われる概念に、カール・ポランニーの暗黙知(tacit knowledge)がある(ポランニー 2009)。私たちは言葉にできる以上のことを知っており、その暗黙的知識にポランニーは暗黙知という名をつけた。ポランニーが挙げている例のうち、「顔の識別」などは理解未満の身体知という扱いでよい気がするが、科学を支える暗黙知などは理解の側に位置づけるべき知識かもしれない。この辺りの扱いは、第3回を書く際の個人的な課題として残る。 ↩
-
このブログが掲載されているウェブサイト。 ↩
-
どの外部モデルを信用できるのか、というのも大きな課題だ。法哲学者の大屋雄裕は、AIを信用する際のあり方として、代理・権威・信託の3種類があり、それぞれに求められる技術や社会的な条件が異なることを指摘している(大屋 2024)。フェイクニュースが溢れる情報環境では、どの有識者を信じるかがリテラシーとして求められる。山田圭一『フェイクニュースを哲学する』は、「知的自律性」を重要なキーワードとして挙げている。 ↩
-
チャンのいう認識エージェントは、単に世界を受動的に捉えるだけでなく、つねに目的(aim)をもってアクション(行動)を起こす。チャンは、認識エージェントの目的そのものが変わりうる。チャンは、自身の行動(action)をその目的(aim)と整合させることができるときに、その認識エージェントは真理をつかんだことになるのだという、極めてプラグマティックな真理・実在観を打ち出している。ハソク・チャンの哲学を読み解いて本連載の文脈の中で論じるのは今の私にはできないが、今後の挑戦としたい。 ↩








 第1回:LLMは理解しているのか?
第1回:LLMは理解しているのか?





